GraphRAG geoespacial em comparação com RAG vetorial
- João Ataide
2.jpeg/v1/fill/w_320,h_320/file.jpg)
- 2 de mar.
- 11 min de leitura
Projetos com RAG raramente falham por falta de dados, os problemas sempre costuma ser outro. Os dados existem, mas o método de recuperação nem sempre sustenta perguntas que dependem de relações entre entidades, principalmente quando essas relações não estão explícitas no texto. Em muitos casos, o sistema recupera trechos semanticamente relevantes, mas não consegue comprovar conexões como proximidade, coocorrência territorial, dependência entre categorias ou encadeamento de evidência. fazendo com que o resultado tenda até ter uma ser uma resposta plausível, porém difícil de auditar.
Neste artigo, sigo a linha dos anteriores e apresento um pipeline pensado para comparar, na prática, um RAG vetorial tradicional e um GraphRAG, neste vou continuar utilizando o mesmo conjunto do OpenStreetMap (OSM), e aplicar sobre ele a discretização territorial com H3 e contruir o nosso grafo com relações espaciais para apoiar perguntas que exigem evidência relacional. Ao invezer de validar somente a qualidade do texto gerado, vamos fazer um experimento e comparar o que cada abordagem recupera, quais vínculos consegue demonstrar e como isso afeta rastreabilidade e verificação.
A primeira estratégia é um baseline vetorial. Nela, cada POI vira um documento curto, e a recuperação ocorre por similaridade semântica via embeddings. Já a segunda estratégia é o GraphRAG. Nesse fluxo, a recuperação inicial ocorre por zonas territoriais, e a evidência é construída ao explicitar relações de proximidade entre categorias, com distância e IDs da região. Em outras palavras, o LLM recebe não apenas itens, mas pares e vínculos entre eles que justificam a resposta.
Recorte do território e categorias do diagnóstico
O ponto de partida é definir o recorte espacial com um centro em latitude e longitude e um raio em metros para consulta na base do OSM. Aqui, vamos usar um raio de 5 km, suficiente para capturar diversidade de registos e, ao mesmo tempo, permitir inspeção manual dos resultados em mapa.
Em seguida, vamos definir as categorias de POIs que possam garantir variação e cobertura para as perguntas para o teste. No conjunto vamos incluir waste_disposal, recycling, fountain, park e water_point. De maneira geral, a escolha não tem como objetivo representar toda a infraestrutura ambiental urbana, e sim formar um conjunto consistente de entidades para testar perguntas relacionais. Além disso, para reduzirmos fragmentação de vocabulário, drinking_water é normalizado como water_point, evitando que a mesma ideia apareça como categorias diferentes.
Coleta de dados no OSM com Overpass e cache local
A coleta usa a Overpass API, consultando entidades por filtros de tags dentro da área definida pelo raio de busca.
Para reduzir dependência de rede e deixar o processo mais fácil de reexecutar, vamos criar um cache local no formato JSON, para evitar repetir chamadas em ajustes iterativos e diminui inconsistências causadas por variações momentâneas da API. Além disso, alguns testes de tentativas com espera progressiva, timeouts, limites de taxa e instabilidade.
No recorte do exemplo, a coleta retorna 411 POIs e 6.407 vias.Preparação dos dados e discretização territorial
Com os dados brutos, extraio dois DataFrames, um para POIs e outro para vias, e realizar a normalização das categorias para reduzir ambiguidade, remoção de duplicidades por osm_id, padronização de coordenadas em float e cálculo do identificador H3 por entidade, criando uma camada territorial discreta.
Dimensões do DataFrame de POIs (411, 7) e Dimensões do DataFrame de Roads (6407, 7)Realizamos a discretização do h3 usando a resolução 7, sendo esse o passo para não mais tratar o território como um contínuo, passo a operar por zonas. Isso facilita agregação, ranqueamento e recuperação por embeddings, além de reduzir o espaço de busca quando preciso construir evidência relacional.
Antes de avançar, vamos dar uma olhada rápida de como está o dataset, realizando a contagens por categoria ajudam a identificar desequilíbrios e a calibrar expectativas.

Agora vamos checar e visualizar com o Folium e MarkerCluster e checar a sanidade dos dados.
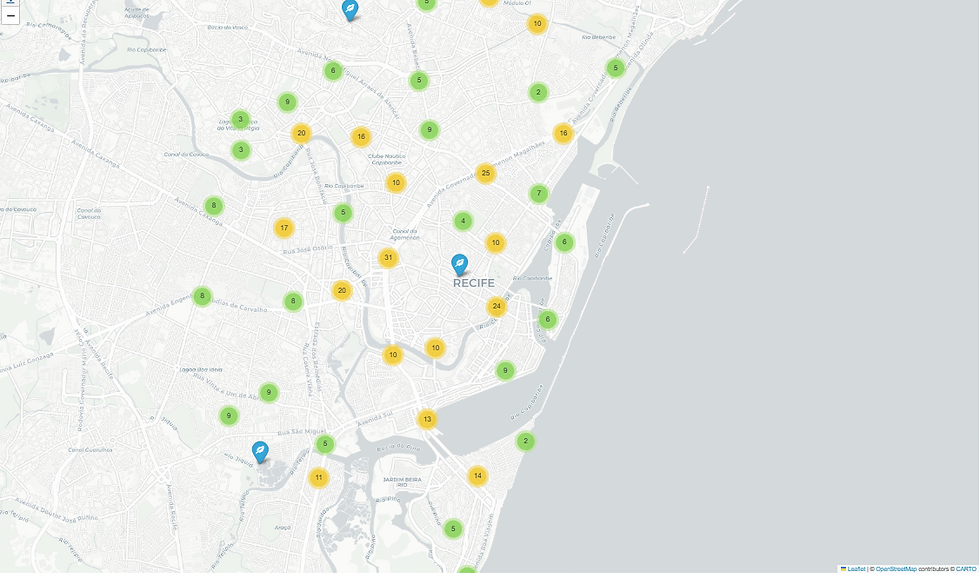
Grafo base e relações estruturantes
É claro que o grafo é a base do GraphRAG porque materializa relações que um índice vetorial não representa de forma explícita.
Na modelagem adotada, cada POI vira um nó no padrão poi:<id>, cada célula H3 vira um nó zone:<h3>, cada categoria vira um nó svc:<amenity> e cada via vira um nó road:<id>.
Em seguida, o grafo recebe relações estruturantes. A relação IN_ZONE conecta POIs e vias à sua zona H3, enquanto IS_A conecta POIs à categoria de serviço. Mesmo antes das relações de proximidade, essa estrutura já permite perguntas sobre composição por zona e distribuição de categorias.
Tivemos 6839 nodes e 7229 edgesRelações espaciais entre POIs por proximidade
A maior parte das perguntas relacionais depende de proximidade. Por isso, temos que criar arestas NEAR entre POIs quando a distância fica abaixo de um limite, neste caso 500 m, com teto de até 10 vizinhos por POI.
Para reduzir custo, agrupo os POIs por célula H3 e busco candidatos na própria célula e em um anel adjacente usando grid_disk. A distância é calculada com Haversine e as arestas armazenam dist_m, que vira evidência explícita de proximidade.
100%|██████████| 411/411 [00:00<00:00, 2540.21it/s]
3529 8359Essa parte é o que diferencia o GraphRAG do baseline vetorial, o baseline tende a recuperar itens semanticamente parecidos, mas não garante que estejam próximos no território e não entrega, por padrão, um conjunto de pares que satisfaça a restrição, o que limita a atuação do processo.
Conectividade aproximada entre vias
Além de proximidade entre POIs, temos que realizar a criação de CONNECTS entre vias que compartilham pontos amostrados da geometria, basicamente a estratégia quantiza coordenadas para capturar interseções aproximadas e reduzir comparações. Mesmo quando essa relação não entra diretamente no comparativo de respostas, ela agrega valor ao abrir espaço para análises futuras de conectividade e acessibilidade.
100%|██████████| 6407/6407 [00:00<00:00, 138242.22it/s]
1785Documentos e embeddings para o baseline vetorial
No baseline vetorial, cada POI é representado como um documento textual curto contendo ID, nome, categoria, coordenadas e zona H3. Além disso, incluir explicitamente o ID, o H3 e as coordenadas ajuda a reduzir ambiguidades quando o LLM precisa justificar a localização.
Em seguida, geramos os embeddings desses documentos utilizando o modelo text-embedding-3-small e realizamos a verificação de similaridade por meio de cosine similarity. Quando a pergunta é recebida, seu embedding é calculado e comparado com o corpus vetorial. Os itens mais similares são então selecionados e utilizados como contexto para a etapa de geração.
100%|██████████| 4/4 [00:01<00:00, 2.08it/s](411, 1536)Esse fluxo é simples e eficiente. Ele funciona bem quando a pergunta é descritiva ou de listagem. A limitação aparece quando a consulta exige relação verificável, como proximidade entre categorias. Nesse caso, a similaridade semântica pode recuperar itens corretos em tema, mas geograficamente dispersos, sem formar pares que satisfaçam a restrição. O modelo passa então a inferir conexão a partir de texto, e não a partir de evidência estrutural.
Zonas como documentos no GraphRAG e sumários
Já no GraphRAG, a recuperação não começa pelas entidades individuais, mas pelas zonas territoriais. Cada célula H3 é transformada em um documento que sintetiza o perfil da área, incluindo total de ativos e categorias predominantes. Para as zonas mais densas, é gerado um breve sumário executivo com o LLM, com foco em caracterizar o padrão territorial de forma clara e estruturada.
Essa etapa de sumário tem dois objetivos principais. Primeiro, melhorar a qualidade da recuperação por embeddings, já que textos que descrevem o perfil da zona tendem a representar melhor seu contexto do que simples contagens. Segundo, deixar explícito que se trata de uma leitura baseada em dados abertos, evitando que o sumário seja interpretado como diagnóstico oficial ou exaustivo.
100%|██████████| 1/1 [00:00<00:00, 2.88it/s]
15 (15, 1536)Entendimento da pergunta e extração controlada
Em perguntas relacionais, um erro comum não é o LLM não responder. O erro é o processo não traduzir a pergunta em restrições recuperáveis. Para reduzir esse risco, vamos precisar usar um schema JSON para extrair serviços e pares de serviços que devem estar próximos, raio em metros, dica de lugar e quantidade de zonas na recuperação inicial.
E vamos precisar criar uma função de parsing para impor um limite e valores padrões, evitando raios irreais e garantindo que perguntas vagas não quebrem o fluxo, e aplicar um fallback, para casos que a pergunta envolva menos de dois serviços e não vier nenhum par de proximidade, crio um par padrão com raio, preservando a natureza relacional do problema.
Como o GraphRAG constrói evidência?
O GraphRAG opera em duas camadas. Na primeira, ele recupera as zonas mais relevantes a partir de embeddings de zona. Em vez de buscar diretamente POIs individuais, rela ranqueia células H3 que tenham um perfil mais compatível com a pergunta, reduzindo o espaço de busca e evitando varrer o território inteiro.
Na segunda camada, eu contruí evidência relacional dentro desse recorte. Ela filtra os POIs contidos nas zonas recuperadas e aplico restrições por categoria de serviço. Quando a pergunta envolve proximidade entre categorias, amplia gradualmente o anel de busca em H3 até obter cobertura suficiente, ou até atingir um limite. Com o conjunto candidato definido, eu calculo pares próximos entre as categorias solicitadas dentro do raio informado e registo a distância em metros, o que vira evidência explícita para sustentar a resposta.
Por fim, eu monto o contexto que vai para o LLM em três blocos. O primeiro resume as zonas recuperadas e seus escores. O segundo lista os POIs filtrados com ID, categoria, coordenadas e H3. O terceiro descreve as relações encontradas, incluindo os pares e suas distâncias. Na prática, isso desloca o trabalho do modelo de inventar conexões para explicar conexões já verificadas, enquanto o baseline vetorial tende a recuperar itens semanticamente próximos e deixa a construção do vínculo por conta da geração.
Visualização dos resultados no mapa
Para comparar as duas abordagens de forma que possamos ver os resultados, vamos incluir uma etapa de visualização. A ideia é simples. Plotar os POIs recuperados e, quando houver evidência relacional, desenhar as ligações entre pares próximos. Isso facilita inspeção manual e ajuda a identificar rapidamente limitações do processo de recuperação.
No baseline vetorial, a visualização mostra apenas os POIs retornados pela busca por similaridade. Como não há relações explícitas nesse fluxo, o mapa serve principalmente para verificar dispersão territorial.
Já o GraphRAG, a visualização inclui também as arestas, as linhas são desenhadas entre os POIs, os quais passam pela restrição de proximidade e ilustrando assim as distâncias.
Experimento comparativo e avaliação
Para realizar o experimento, vamos utilizar perguntas explicitamente relacionais. Elas envolvem explicitamente a proximidade entre categorias, exigindo mais do que simples recuperação temática. O objetivo é observar como cada abordagem responde quando a pergunta depende de vínculo verificável entre entidades.
Para cada pergunta, vamos executar o baseline vetorial e o GraphRAG, não apenas registando os textos das respostas. Também vamos realizar o armazeno os IDs, as zonas ranqueadas, os pares encontrados e o subconjunto de evidência utilizado na geração. Dessa forma, a comparação não se limita à qualidade narrativa. Ela considera o que cada método efetivamente recupera e com que sustentação estrutural.
As perguntas utilizadas no teste são as seguintes com tema de levantamento e análise de estruturas ambientais:

Perguntas prostas para o teste, proximo passo é executar para ambas as abordagens para cada pergunta e consolido os resultados em uma estrutura comparável, que inclui respostas textuais e evidências recuperadas:
Nos testes realizados com essas perguntas, a diferença entre as abordagens fica clara. Em alguns casos, o baseline vetorial retorna itens semanticamente coerentes com o tema da consulta, mas não apresenta pares explícitos que comprovem a relação solicitada. A conexão entre os elementos aparece no texto, mas não está necessariamente sustentada por evidência estrutural.
Já o GraphRAG tende a produzir respostas mais ancoradas em vínculos verificáveis. Mesmo quando o texto é mais conciso, ele vem acompanhado de pares com distância mensurável e identificação das zonas envolvidas. Isso torna a resposta mais auditável, pois permite rastrear exatamente quais entidades foram conectadas e sob qual critério espacial.
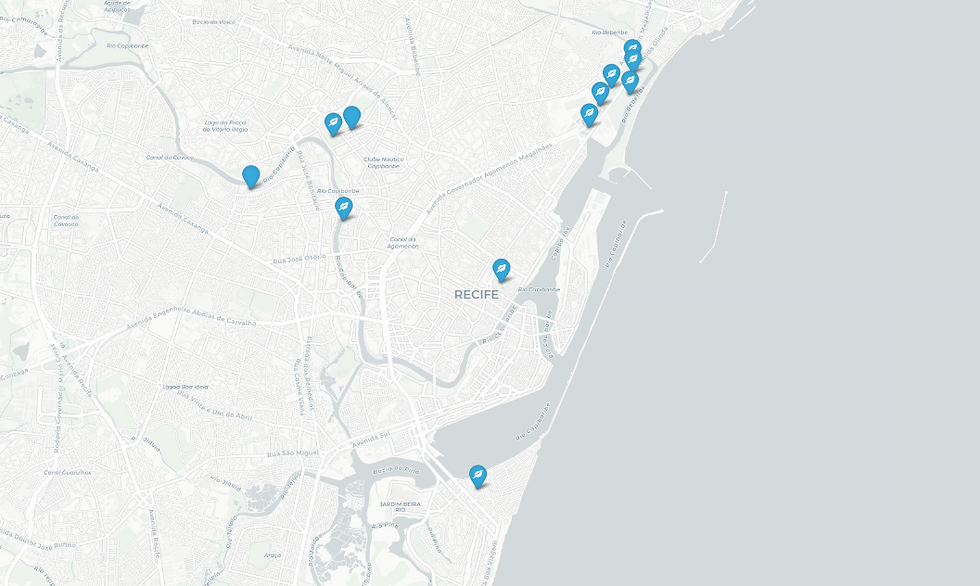
Também realizo testes unitários pontuais para inspecionar o comportamento de cada abordagem isoladamente. Por exemplo, ao perguntar quais pontos de reciclagem ficam perto de parques, posso visualizar o resultado do baseline em texto e, no caso do GraphRAG, inspecionar o subgrafo gerado no mapa:


Para garantir uma avaliação repetível e estruturada, precisamos configurar um LLM para atuar como juiz, utilizando um schema explícito de validação. Esse juiz mede critérios como groundedness (grau de fundamentação no contexto fornecido) e aderência às restrições, por exemplo, responder exclusivamente com base no contexto disponibilizado e citar corretamente os IDs relevantes.
Embora essa abordagem não substitua a revisão humana, ela permite identificar padrões, inconsistências e desvios iniciais de forma sistemática e escalável.
Vamos chamar o juiz que vai medir e verificar a aderência das respostas.
A avaliação pelo juiz LLM mostra que o baseline apresentou médias ligeiramente superiores, com groundedness de 4.75 e aderência a restrições de 5.00, enquanto o GraphRAG obteve 4.25 e 4.75, respectivamente. Em praticamente todas as consultas, o baseline manteve notas altas, o que indica boa coerência textual, citação adequada de IDs e respeito às instruções do prompt. Do ponto de vista estritamente textual, ele se mostrou consistente e bem comportado.
No entanto, essa métrica avalia alinhamento entre resposta e contexto fornecido, e não a qualidade estrutural das relações recuperadas. O GraphRAG pode ter notas ligeiramente menores em groundedness quando retorna respostas mais conservadoras ou evidencia limitações explícitas de cobertura. Ainda assim, ele oferece vínculos verificáveis e distâncias mensuráveis, algo que o juiz textual não captura completamente. Por isso, a análise precisa ser complementada por métricas relacionais, que avaliam a recuperação efetiva das relações pedidas.
Métrica relacional com precisão e cobertura
Como o objetivo do GraphRAG é recuperar relações, a avaliação vamos precisar verificar se os pares retornados realmente correspondem a relações válidas no grafo. Para isso, vamos precisar definir duas funções centrais para para a comparação, ground_truth_pairs e relational_accuracy.
A função ground_truth_pairs constrói o conjunto de referência para cada combinação de categorias e raio definida na consulta. Ela percorre as arestas NEAR já existentes no grafo e filtra apenas aquelas que conectam dois POIs das categorias solicitadas e que respeitam a distância máxima. O resultado é um conjunto de pares únicos de IDs que representa todas as relações válidas no território para aquela restrição. Esse conjunto funciona como verdade operacional independente do processo de recuperação por embeddings.
Em seguida, a função relational_accuracy compara os pares efetivamente recuperados pelo GraphRAG com esse conjunto de referência. A partir dessa comparação, calcula precision, recall e F1. A precision mede quantos dos pares recuperados são de fato válidos. O recall mede quantos dos pares válidos existentes foram encontrados. O F1 equilibra os dois, oferecendo uma visão sintética do desempenho relacional.
Vamos agora aplicar nos testes e calcular as métricas.
Os resultados mostram comportamentos distintos entre as consultas. Nas consultas 0 e 3, observa-se um bom equilíbrio entre precision e recall, com F1 de 0.7119 e 0.8060, respectivamente. Isso indica que o sistema conseguiu recuperar majoritariamente relações corretas, mantendo cobertura satisfatória do conjunto de referência, com 21 de 32 e 27 de 32 relações válidas identificadas. Nesses casos, há consistência entre o que existe no grafo e o que foi efetivamente recuperado.
Na consulta 1, o cenário é diferente. O recall é 1.0, o que significa que todas as relações relevantes foram encontradas. No entanto, a precision é 0.4, evidenciando que uma parcela significativa dos pares retornados não pertence ao conjunto válido. O sistema foi abrangente, mas introduziu ruído ao incluir relações que não satisfazem estritamente a restrição definida.
A consulta 2 apresenta F1 igual a 0, mas com gt_size igual a 0, o que indica ausência de relações esperadas no território para aquela combinação de categorias e raio. Nesse caso, o resultado é semanticamente neutro, pois não havia relações a serem recuperadas. O valor zero decorre da definição matemática das métricas, não de um erro de recuperação.
Já as médias dos resultados, tivemos precision 0.4873, recall 0.6250 e F1 0.5223 mostram que o sistema tende a recuperar boa parte das relações relevantes, com recall superior à precision. Isso sugere uma estratégia mais sensível do que específica. Há boa capacidade de cobertura, mas ainda com ruído considerável, indicando espaço para melhorias.
Considerações finais
O baseline que é o RAG vetorial é eficiente, simples e de menor custo computacional. Ele funciona bem para perguntas descritivas ou de listagem, nas quais a similaridade semântica é suficiente para recuperar entidades relevantes. Sua principal limitação surge quando a consulta exige vínculos verificáveis, como proximidade ou integração, pois pode retornar itens corretos de forma isolada, deixando para o LLM a tarefa de inferir conexões que não estão explicitamente sustentadas.
Por outro lado, GraphRAG adiciona uma camada estrutural ao processo de recuperação. Ao operar sobre zonas e construir pares com distância mensurável, ele transforma restrições da pergunta em evidências, aumentando rastreabilidade. No final, o teste para mim deixou claro os dois métodos não competem diretamente, mas respondem melhor a problemas diferentes. Quando a pergunta é relacional e exige prova de vínculo, a abordagem usando grafo tende a ser mais adequada. Quando a tarefa é predominantemente descritiva e o custo precisa ser reduzido, com certeza vale muito mais utilizar o RAG vetorial.


Comentários